The AI Data Supply Squeeze: Understanding the Market Before Enterprise Adoption

The supply squeeze is real, and the market dynamics are shifting. Inside the untapped market for authenticated gameplay data
Key Points
- AI companies pay $130M/year (Reddit), $250M+ (News Corp) for training data, proving enterprise willingness to pay premium rates for strategic datasets.
- Authenticated gameplay data shows massive scarcity: while AI labs train on datasets containing trillions of words and billions of images, public authenticated gameplay datasets remain under 1,000 hours (MineRL ~500 hours, other datasets smaller). Direct comparisons across data types have limitations, but the relative scarcity is clear.
- Major gaming platforms prioritize game distribution over enterprise AI data partnerships, lacking specialized infrastructure for authenticated data capture.
- Infrastructure deployment typically precedes enterprise procurement cycles (6-12 months), creating temporal separation between platform development and enterprise contract execution.
The Data Licensing Gold Rush
The AI training data market is experiencing rapid price discovery as labs race to secure strategic datasets.
Reddit licensed its content to Google and OpenAI for approximately $130 million annually (estimated $60M/year to Google, $70M/year to OpenAI based on reported revenue mix), disclosed in Reddit’s 2024 SEC S-1 filing. News Corp signed a deal exceeding $250 million for five years of news archive access. Apple paid Shutterstock $25-50 million to license image data. Academic publishers are securing $10-23 million per archive.
Video data, which requires more complex processing, trades at $1-4 per minute depending on quality and exclusivity. At scale, that’s $60-240 per hour of authenticated content.
These deals prove two things: enterprise AI labs have deep budgets for strategic data, and data pricing follows scarcity economics. When demand is inelastic and supply is constrained, price discovery accelerates. Text data went from free APIs to $130 million annual contracts in under 18 months.
But the market is mispricing what comes next.
The Supply Gap: What AI Actually Needs
The issue isn’t technical, it’s strategic. AI labs aren’t primarily building chatbots anymore. Google launched Genie 3 on August 5, 2025. NVIDIA announced Cosmos world foundation models at CES 2025 (January 6, 2025), partnering with Boston Dynamics, Figure AI, and others for robotics simulation. With major labs pursuing embodied world models, the inflection point for behavioral data pricing isn’t theoretical. It’s underway.
World models need something text and image archives can’t provide: authenticated human gameplay showing real decision-making in complex visual environments. As detailed in our analysis of the AI training data market (see: “The AI Data Bottleneck”), synthetic data proved insufficient and existing gameplay datasets remain orders of magnitude too small.
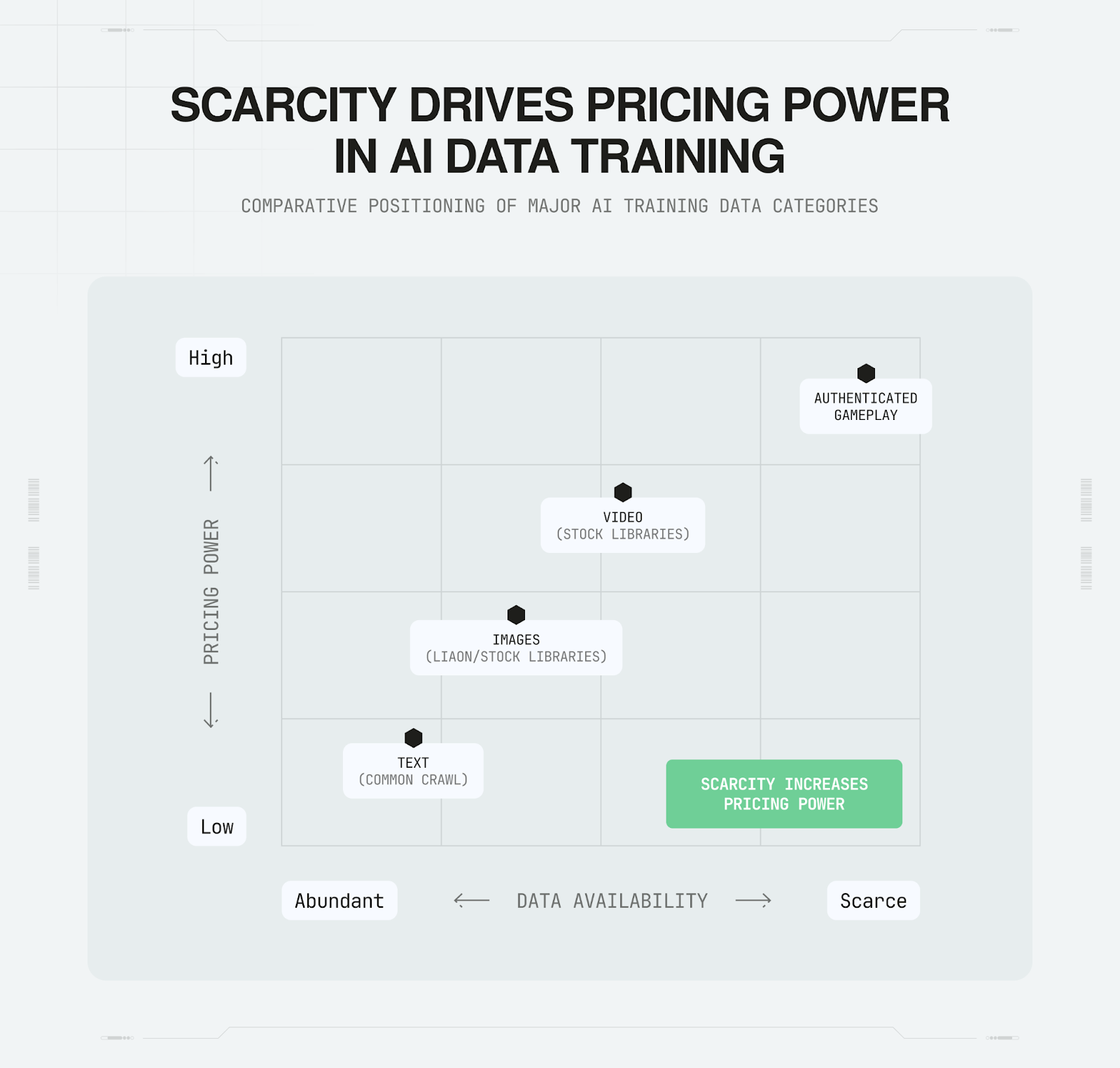
The scarcity is stark when comparing authenticated datasets across AI categories. AI labs train language models on datasets like Common Crawl (containing trillions of words) and image models on billions of samples. But authenticated human gameplay data remains limited: MineRL, one of the largest public datasets, contains roughly 500 hours of human demonstrations. While direct numeric comparisons across different data types (tokens vs. hours vs. images) have limitations, the relative scarcity is clear: text and image training data exist at massive scale, while authenticated gameplay data remains in the hundreds of hours globally.
What is “authenticated gameplay”? Synchronized video frames paired with player input logs (keystrokes, mouse movements), environment state data, and cryptographic attestation of capture—all with verifiable operator opt-in. This goes beyond standard video data, which lacks the input-level telemetry world models require.
Given that standard video data trades at $1-4 per minute, authenticated gameplay data (video + input telemetry + provenance) would command a premium over commodity video rates. This is purely hypothetical speculation for illustration: if authenticated gameplay data were priced conservatively at $2/minute (based on video data comparisons), 10,000 hours would represent a $1.2 million dataset before any recurring licensing or fine-tuning contracts. No established market pricing exists for authenticated gameplay data - this calculation is speculative and intended to show potential scale rather than predict actual pricing. The market value potential exists. The supply doesn’t.
To grasp the magnitude of scarcity, here’s how authenticated gameplay compares to every other data category driving today’s AI models:

Supply figures reflect public, openly licensed datasets; proprietary/private datasets are not publicly quantifiable.
No other data class has such a combination of high behavioral richness and limited enterprise-scale supply.
Why No One Has Unlocked What AI Actually Needs
While gaming platforms capture immense gameplay activity, the gap lies in how that data is authenticated, consented, and prepared for enterprise use.
Major gaming platforms host vast gameplay activity but weren’t designed to commercialize it as an authenticated data layer.
While these platforms technically have user data sharing capabilities (Epic’s privacy policy allows sharing de-identified data “for any reason permitted by law”), their business models focus on game distribution and content delivery rather than enterprise AI data partnerships. They weren’t architected with consent-first data capture or the provenance systems that meet enterprise AI compliance requirements.
Platforms like Steam, Epic, and Twitch prioritize gameplay access, game sales, and content streaming over the specialized infrastructure required for authenticated data capture at enterprise scale.
Twitch hosts massive gameplay video archives but lacks input-level telemetry (the specific player actions and decisions that world model training requires). The platform was built for streaming, not data licensing.
Cloud gaming services (GeForce NOW, Xbox Cloud) process gameplay at scale but treat player input and video as proprietary, using it for quality-of-service analytics rather than third-party licensing.
Shaga’s approach differs fundamentally: it builds a consent-first infrastructure that captures gameplay telemetry and input data directly from opt-in node operators, not from platform archives or user-generated streams. No publisher or platform data is redistributed; only consented and authenticated performance signals from Shaga’s network are captured, processed, and licensed in compliance with enterprise requirements.
In short, existing platforms were built to deliver gameplay experiences, not authenticated data supply. Shaga was built for both.
Why Shaga’s Supply Unlock Is Defensible
Unlocking authenticated gameplay data at enterprise scale requires capabilities that create compounding advantages.
First, the technical moat. Shaga is building gaming infrastructure and data capture infrastructure simultaneously. Competitors face two options: retrofit existing gaming platforms (breaking user expectations and consent frameworks) or build dual-use architecture from scratch (expensive, time-intensive, requires gaming platform expertise).
Second, the timing advantage. Shaga identified the supply constraint early and architected for it from inception. By the time the supply squeeze becomes obvious to competitors, Shaga will have operational data capture with established node operator relationships and enterprise compliance frameworks.
Third, the network effects. More gamers create more diverse gameplay data, which increases enterprise value. As detailed in our supply squeeze analysis, diversity in player behavior directly improves training data quality. The platforms that scale first capture the most valuable, diverse datasets.
When enterprise buyers evaluate suppliers, they’ll prioritize platforms with proven data capture, and diverse gaming datasets. Early infrastructure builders who reach scale before market consolidation establish category leadership.
The Infrastructure-to-Enterprise Timeline
Here’s the market dynamic: procurement friction and compliance requirements mean enterprise validation typically lags infrastructure deployment by six to twelve months.
The timing signals are concrete: Google Genie 3 launched August 5, 2025, NVIDIA’s Cosmos launched at CES January 2025 with partnerships including Boston Dynamics and Figure AI, and $45 billion in VC flowing to generative AI in 2024 alone. The platforms that unlock authenticated gameplay data supply before market consolidation are positioned to establish category leadership.
Why This Matters Now
The countdown has already started.
Data pricing follows scarcity economics. When demand is inelastic (AI labs need this data to compete) and supply is fixed (no platforms can license it), price discovery events happen fast. That’s why text data went from free APIs to $130 million per year contracts in under 18 months.
If Reddit’s text comments command $130 million annually, what’s authenticated human gameplay worth? More complex visually, more decision-rich behaviorally, and orders of magnitude scarcer in available supply.
The supply squeeze isn’t speculation. It’s documented: enterprise demand exists (Google Genie, world model race), enterprise budgets exist (Reddit and News Corp deals prove willingness to pay), but openly licensed enterprise supply doesn’t exist as of Q3 2025 (Steam/Epic don’t openly license under current terms, barriers are structural).
Shaga’s dual-revenue model is architected to unlock this supply. When B2B data licensing goes operational, the market will price what authenticated, consented, enterprise-compliant gameplay data is worth. Infrastructure development precedes that pricing discovery.
The Category Evolution
DePIN networks are evolving toward sustainable, diversified revenue models. Shaga’s dual-revenue architecture is designed to address this evolution from inception.
The market dynamic centers on supply unlock timing: infrastructure development before enterprise buyers create pricing pressure. The demand signal exists ($45B VC into generative AI). The execution challenge is unlocking supply at enterprise scale.
Reddit sold what AI already has.
News Corp sold what AI already reads.
Shaga aims to license what AI still needs.
Disclaimer: This analysis discusses AI training data market dynamics, authenticated gameplay data supply constraints, and Shaga’s infrastructure architecture - intended for informational and educational purposes, not for solicitation or investment promotion.