The AI Data Bottleneck: Why Authenticated Gameplay Is the Next High-Value Data Category

The AI training data market reaches $9.6B by 2030, but authenticated gameplay data at enterprise scale remains scarce. Shaga is building infrastructure to serve this emerging category.
Key Points
- Market reaching $9.6B by 2030 (22% CAGR); authenticated gameplay emerging as critical for world models
- Synthetic data is insufficient; largest public dataset is ~500 hours, far below commercial needs
- Major gaming platforms lack data licensing infrastructure
- Shaga’s dual-revenue model fills this gap through technical infrastructure, network effects, and timing
The AI world model race just hit an unexpected wall, and it’s not the one anyone predicted.
In August 2025, Google DeepMind unveiled Genie 3, a breakthrough system that generates interactive, real-time 3D environments from text prompts. Within the AI research community, world models (systems that simulate and predict how environments evolve) are now recognized as a critical step toward artificial general intelligence. The applications span text-to-game generation, real-time simulation for robotics training, and interactive experiences that respond to user input at scale.
But as labs race toward this future, they’ve discovered that compute isn’t the constraint anymore. Data is.
The Scale Problem: Thousands of Hours Aren’t Enough
Training a viable world model requires staggering volumes of diverse, high-quality gameplay footage. Current research indicates these systems need thousands to tens of thousands of hours of visual data, action sequences, and decision-making patterns to achieve robust performance. The complexity of the game matters: simple environments like classic Atari might require hundreds of hours, while open-world games like Minecraft demand exponentially more.
The existing public datasets illustrate the gap. MineRL, one of the largest gameplay datasets available, contains roughly 500 hours of authenticated human play. For context, that’s nowhere near the scale needed for commercial-grade world models that must generalize across diverse scenarios, visual styles, and player behaviors.
More troubling: the data must capture authentic human decision-making, not scripted sequences or bot behavior. This is where the industry’s initial optimism about synthetic data began to unravel.
The Synthetic Data Dead End
AI labs initially believed synthetic data (gameplay generated by AI itself) would solve the training problem. It didn’t.
Research from institutions including the UN University and studies published in arXiv reveal why: synthetic data lacks the unpredictability, chaos, and emergent behaviors that define authentic human play. Models trained on over-smoothed, idealized synthetic datasets fail to handle the messy variability inherent in real-world human behavior.
The implications are particularly severe for world models. These systems must learn to predict not just what can happen in an environment, but what would happen when real humans interact with it. Synthetic data, generated by algorithms optimizing for consistency and efficiency, fundamentally cannot replicate the irrational, creative, and context-dependent choices humans make.
Leading research now recommends “prioritizing real-world data, using synthetic mainly as supplement or last resort.” For world model training, that real-world data increasingly means authenticated human gameplay at scale.
Why Gaming Data Specifically
What makes gaming environments uniquely valuable for AI training? The answer lies in the intersection of visual complexity, decision richness, and simulation capabilities.
Modern games offer highly detailed 3D environments with dynamic lighting, varied textures, and environmental conditions that closely mimic real-world scenarios. As one example, researchers have used Grand Theft Auto V to train self-driving car AI, leveraging the game’s realistic rendering to recognize stop signs and navigate streets under conditions that would be costly and time-consuming to replicate in real life.
Beyond visuals, games present multi-level decision-making scenarios: navigation, resource management, adversarial strategy, social interactions, and continuously adapting goals. This decision density creates rich training signals that static video or scripted simulations cannot match.
Perhaps most importantly, virtual game environments can be precisely controlled. Researchers can generate unlimited scenario variations, automatically annotate data at the software level, and iterate rapidly, all without the physical risk or cost constraints of real-world data collection. The controllability, richness, and diversity of gaming environments enable AI training efficiency well beyond what’s practical with most other data sources.
The Market Opportunity: A $9 Billion Data Category
The AI training data market is expanding rapidly. Current market research from Grand View Research, MarketsandMarkets, and other major analyst firms places the global market at approximately $3 billion in 2025, projected to reach $9.6 billion by 2030, representing a compound annual growth rate of roughly 22%.
Within this broader market, image and video datasets currently comprise 41% of revenue, with gaming and simulation data representing a high-value subset. As world model development accelerates, the portion of this market dedicated to authenticated gameplay data is positioned to grow disproportionately. Enterprise AI labs have deep budgets and urgent timelines, making high-quality, compliant data sources increasingly strategic assets.
The Supply Gap: Who’s Capturing This Data?
Here’s the problem: despite clear demand, no major platform is positioned to deliver authenticated gameplay data at enterprise scale.
Consumer gaming platforms like Twitch, Steam, and Epic focus on content distribution and community engagement, not data licensing infrastructure. Research labs generate datasets for academic purposes but lack the scale required for commercial model training. The existing public datasets (while valuable for benchmarking) remain orders of magnitude smaller than what’s needed for production-grade world models.
Enterprise buyers require more than raw gameplay footage. They need consent-first data capture that meets evolving compliance frameworks, authenticated proof of data origin, and the diversity that comes from thousands of unique players across varied gaming scenarios. The technical and legal infrastructure required to deliver this at scale doesn’t yet exist at major platforms.

This gap represents both a market opportunity and an infrastructure challenge: one that requires architecture built for dual use.
How Shaga Is Capturing This Opportunity
The supply gap isn’t just a market observation. It’s the opening Shaga was designed to fill.
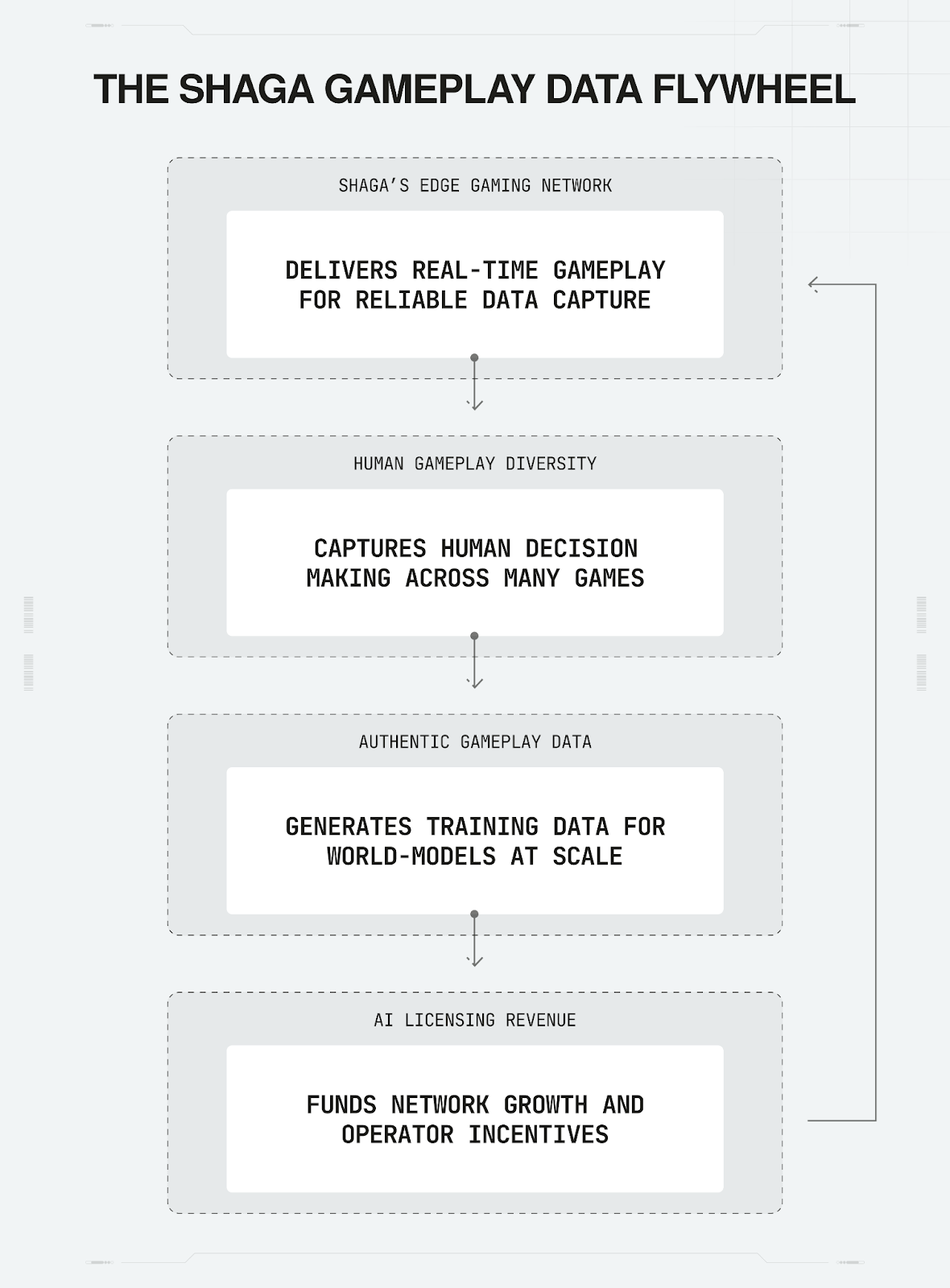
While consumer gaming platforms focus on content distribution and research labs remain limited by scale, Shaga is building infrastructure architected for dual use: deliver low-latency gaming while capturing enterprise-grade authenticated gameplay data.
The platform operates on community-powered edge computing. Node operators who provide gaming PCs to the network enable low-latency cloud gaming for players. These node operators will have the option to participate in authenticated data capture, creating two revenue streams: B2C player subscriptions and B2B data licensing.
The consent-first architecture: Data capture is opt-in for node operators only. This isn’t a retrofit or an afterthought. It’s built into the platform’s core architecture, ensuring compliance with enterprise data governance requirements. Players simply enjoy the gaming experience; node operators choose whether to contribute data and earn associated rewards.
Enterprise-grade authenticated capture (in development): Shaga is building authentication and verification systems to meet enterprise compliance requirements. This positions the platform to serve enterprise buyers while existing gaming platforms would face major technical and legal challenges adding that capability.
This dual-revenue model (detailed in our analysis “Dual Revenue, One Network: The Shaga Model”) creates a strategic positioning: gamers get low-latency play designed to be subsidized by B2B data revenue, while AI labs access authenticated, diverse gameplay data at scale.
Building Moats Through Infrastructure
Shaga’s infrastructure approach creates compounding advantages that are difficult to replicate.
First, the technical moat. Enterprise-grade authenticated gameplay capture requires three competencies: platform engineering (low-latency gaming), data infrastructure (authenticated capture), and compliance frameworks (consent + verification). Shaga is building all three simultaneously. Competitors face two options: retrofit existing gaming platforms and risk breaking user expectations, or build from scratch at significant cost and time.
Second, the network effects. Research on data platform dynamics shows a clear pattern: more users generate more diverse data, which increases value to enterprise buyers, which funds platform growth and attracts more users. For Shaga, diversity in player behavior directly improves training data value. A dataset capturing 1,000 players’ approaches to the same scenario is exponentially more valuable to AI labs than 1,000 hours from a single player. As the user base grows, the data moat deepens and the flywheel accelerates.
Third, the timing advantage. In platform markets, early infrastructure builders who reach scale before consolidation often establish category leadership through accumulated data advantages. Shaga is positioning to establish this advantage before the market consolidates.
The Window Is Now
The decisive constraint in the AI world model race is authenticated human gameplay data at enterprise scale, not compute.
The platforms that solve authenticated gameplay capture in the next 18-24 months, before market consolidation, will establish the data moats and network effects that define category leadership. Based on observable market dynamics (demonstrated AI lab demand, documented synthetic data limitations, $9.6B market projection by 2030), this opportunity is measurable, not speculative.
Shaga’s positioning is distinct: a dual-revenue model, infrastructure architected for data capture (not retrofitted), and consent-first compliance architecture. This creates sustainable unit economics that single-revenue gaming platforms and pure data plays struggle to match.
The timing is concrete. Google’s Genie 3 launch in August 2025 signals accelerating demand for world model training data. The market window for establishing category position is narrow. First movers who build the technical infrastructure, establish network effects, and capture diverse gameplay data before consolidation will define this emerging category.
The platforms capturing authenticated gameplay data at scale, with defensible network effects and operational infrastructure, are positioned to establish category leadership as world models transition from research to production.
Shaga is building to be that platform.
Disclaimer: This analysis discusses the AI training data market, authenticated gameplay infrastructure, and Shaga’s platform architecture - intended for informational and educational purposes, not for solicitation or investment promotion.